And it's a huge distinction since with scratching you generally recognize the target sites, you might not recognize the certain page URLs, however you understand the domain names at the very least. On the other hand, information creeping services are far more sophisticated and also are designed to dig deep right into the internet, despite what their goal could be. They are configured to inspect all the feasible back links up until any related details has actually been meticulously examined. Information scraping is a great approach when you intend to extract some info that is difficult to get to, such as asset prices, for instance. Nevertheless, there are some small downsides to this process.
- Practically every internet scraping device utilizes an HTTP customer behind the scenes to inquire the web site server you are trying to accumulate information from.
- It is approximated that by 2021, they will certainly surpass their less-informed market rivals by $1.8 trillion every year.
- We needed to access a characteristic of the element, which is done utilizing brackets, like how we would access a Python dictionary.
Apify lets me focus on core capability, not managing framework. The biggest benefit is the stability of the Apify platform and also well-documented user interface that permits simple integration with our internal systems. Connect to hundreds of applications as soon as possible using prefabricated integrations, or set up your very own with webhooks and also our API.
Nodejs Internet Scratching Tutorial
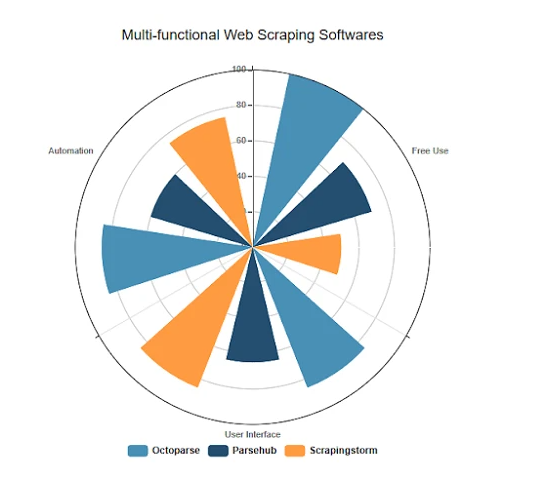
Abigail Jones Nowadays, huge data has been extensively utilized in numerous areas like shopping sites, social media sites, clinical reforms and also financial reports. Although there are lots of stats companies to provide different data sources, unique demands are not typically thought about by such organizations. Individuals or enterprises desire even more information like the specific cost of the product or the get in touch with details of different internet sites. That might be the ground of the website data scuffing service. You can now find there are several website data removal devices readily available online like Import.io and also Octoparse.
Is it lawful to creep information?
Internet scraping as well as creeping aren't prohibited by themselves. Nevertheless, you could scrape or creep your very own web site, easily. Startups love it since it''s an economical and also powerful means to gather data without the need for collaborations.
We import its package right into our task and also create a circumstances of it named crawlerInstance. In the snippet above, we send a message to the moms and dad string utilizing parentPort.postMessage() after initializing a worker thread. After that, we listen for a message from the parent string making use of parentPort.once(). You have actually effectively extracted data from that first web page, however we're not proceeding past it to see the rest of the outcomes. The whole point of a crawler is to find and traverse links to other web pages as well as get hold of data from those pages as well. Currently let's turn this scraper into a spider that complies with web links.
Just How Does Web Creeping Work?
Continuing with the previous instance, when you look for web creeping vs. web scraping, the internet search engine crawls every one of the web's website, consisting of pictures and also video clips. Search engines use web spiders to creep all web pages by following the web links installed on those pages. Internet spiders find brand-new links to other Links as they crawl pages and also include these uncovered links to the crawl line up to crawl following.
SciSciNet: A large-scale open data lake for the science of science ... - Nature.com
SciSciNet: A large-scale open data lake for the science of science ....
Posted: Thu, 01 Jun 2023 07:00:00 GMT [source]
It can be imported from a remote source or handed off to an nonprogrammer with some frontend experience to fill in and also include brand-new web sites to, and also they never need to consider a line of code. Although we, as humans, have the ability to quickly identify the title and also main content of a web page, it is much more tough to get a bot to do the very same point. An efficient means of programming is to encapsulate repeatedly used code in a particular feature. This feature after that can be called with particular parameters, process something as well as return a result.
In the above paragraph, I mentioned these devices with corresponding web links. I extremely recommend you examine them out before diving into the instance. As soon as you have that, you intend to recognize the one-of-a-kind tags that are around the cost so you can make use of that in your information scrape. Some good tags would certainly be div tags with IDs or very details class names. There are currently data scrapingAI on the market that can utilize machine learningto keep on getting better at recognising inputs which only people have actually commonly had the ability to translate-- like pictures. Feeding item data from your website to Google Shopping and other 3rd party sellers is a key application of data scraping for e-commerce.
As the web crawler analyzes as well as fetches the URL, it will find brand-new links installed in the page. To determine which is finest for your demands or how to combine them for your internet scuffing project, you need to recognize the differences in between web scuffing as well as web crawling. Their functionality differs in degrees, and you can pick from the ones offered, depending upon whichever matches your standards for information requirement the most. However, Have a peek here only a few handle to go far in the information market, the reason being that the work of a reliable web crawler is not as easy one. Information scratching has actually come to be the utmost tool for organization development over the last years.
This is where web Custom ETL Services as well as information scuffing applications come in handy. You can set these scuffing applications to check out web sites and also remove the content/data that you want. The noticeable advantage of this is having the ability to obtain the exact information that you want easily and successfully. Information scraping is the procedure of utilizing an application to essence beneficial details from a website. This will certainly allow us to obtain big amounts of data from sites in a brief quantity of time.
https://maps.google.com/maps?saddr=619-2%20Carlton%20St.%2C%20Toronto%2C%20ON%20M5B%201J3%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
Its primary function is to send browser-like demands to the web server. This function enables the scraping bot to blend in with the site traffic, making it much less likely to be discovered and also obstructed. Following this same reasoning, HTML analyzing libraries such as Cheerio as well as BeautifulSoup parse data straight from Custom ETL Services website so you can utilize it in your jobs and applications.
Perceptions of dietary intake amongst Black, Asian and other ... - bmcnutr.biomedcentral.com
Perceptions of dietary intake amongst Black, Asian and other ....
Posted: Thu, 13 Jul 2023 09:42:14 GMT [source]
What is the difference in between junking and also crawling?
Internet scuffing aims to draw out the information on web pages, as well as internet creeping objectives to index and find web pages. Web crawling entails following links permanently based on hyperlinks. In contrast, internet scratching indicates writing a program computer that can stealthily collect information from numerous sites.