If done correctly by people who recognize what they're doing, these programs will provide you the critical assistance you need to be successful in your sector. Data scraping solutions can accomplishing activities that can not be executed by software program crawling tools. Things like javascript execution, entry of information layouts, defying robotics policies-- all are a thing information scraping solutions can deal with. Nevertheless, we will discuss how online search engine take advantage of internet spiders.
- In an initial exercise, we will certainly download and install a solitary websites from "The Guardian" and also extract text along with relevant metadata such as the article day.
- However after reading this write-up, we hope you'll be clear regarding the context, the points of distinction, and the use of both.
- This is something that deserves its own post, but for now we can do fairly a great deal.
Proxies can be used to make requests, and conceal the information of requests made. When making a request for you, proxies don't offer your IP address. As pointed out above, among the benefits of using node-crawler is that it lets you customize your web-scraping tasks and include traffic jams to them. The approach we carried out over usages 2 various plans, Axios and also Cheerios, to bring and also traverse websites. An alternate web spider we can make use of is node-crawler, which makes use of Cheerio under the hood and comes with extra capabilities that permit you to personalize the means you creep and scrape websites. Going forward, we will certainly update the main.js file so we can appropriately layout our output and send it to our worker string.
Discover
Abigail Jones These days, big data has been widely utilized in different locations like ecommerce internet sites, social media sites, medical reforms and monetary reports. Although there are lots of statistics companies to provide different databases, special requirements are not typically thought about by such organizations. Individuals or business want more information like the details cost of the product or the get in touch with info of various internet sites. That might be the ground of the site information scraping solution. You can currently discover there are lots of web site data removal devices readily available online like Import.io and Octoparse.
What is the distinction between ditching and creeping?

Web scuffing objectives to extract the data on websites, as well as web creeping objectives to index and also find websites. Web crawling entails following web links permanently based on hyperlinks. In comparison, web scraping implies creating a program computing that can stealthily accumulate data from several sites.
Selenium logoBecause of its capacity to provide JavaScript on a website, Selenium can assist scrape dynamic web sites. This is a convenient feature, considering that numerous contemporary websites, particularly in ecommerce, usage JavaScript to load their content dynamically. Selenium is mostly a browser automation tool created for internet screening, which is additionally found in off-label usage as an internet scraper. It utilizes the WebDriver protocol to manage a headless browser as well as perform activities like clicking switches, completing types, and also scrolling. Parsing, on the other hand, implies examining as well as transforming a program into a layout that a runtime environment can run. Many thanks to Node.js abilities, the JavaScript ecosystem has a range of extremely efficient web scratching collections such as Got, Cheerio, Puppeteer, and also Dramatist.
Just How Does Web Crawling Job?
Mean you want to get large amounts of information from a site as swiftly as possible. In this article, we will speak about data scratching and also how to scrape the web. Additionally, we'll get involved in what information scraping is, why you would certainly wish to do it, how data scrapers job, and also lastly, we'll discuss various processes for scratching the internet.
As a result of that, both collections have many similarities, reducing the discovering curve as well as reducing the headache of migrating from one collection to an additional. Internet browsers are a method for people to access as well as connect with the details readily available on the web. However, a human is not always a requirement for this communication to happen. Internet browser automation devices can mimic human activities as well as automate a web internet browser to carry out repeated and also error-prone jobs. The goal of the project is to make HTTP requests less complex as well as much more human-friendly, for this reason the title "Requests, HTTP for human beings." Got Rub is a contemporary plan extension of the Got HTTP customer.
Although the applications of web crawlers are virtually countless, huge scalable spiders have a tendency to fall into one of numerous patterns. By learning these patterns as well as acknowledging the scenarios they relate to, you can vastly enhance the maintainability as well as toughness of your internet crawlers. Currently we can repeat over all Links of tag introduction pages, to accumulate more/all web links to articles marked with Angela Merkel. We iterate with a for-loop over all Links as well as add results from each single link to a vector of all links. Currently, web links has Affordable web scraping services a listing of 20 links to solitary posts labelled with Angela Merkel. HTML/ XML things are a structured depiction of HTML/ XML source code, which allows to extract single aspects (headlines e.g.
- Internet spiders arrange the pages as well as also analyze the quality of material as well as execute many various other features to accomplish the indexing as an outcome.
- The-- sup flag is used to develop a brand-new job with an OTP skeletal system, consisting of the supervision tree.
- Why refrain it vice versa, accumulating all topics from one website, and after that all topics from the next internet site?
- The requirement for internet information crawling has actually gotten on the surge in the past few years.
- Information scraping is very important for a business, whether to acquire customers or service and income growth.
- Remember that you've only scratched the surface area of what Crawly can do, and much more effective features are offered.
Now we can make use of that function scrape_guardian_article in any other component of our manuscript. We make use of a running variable i, taking worths from 1 to size to access the single links in all_links and create some progress output. I wished this write-up on data scraping was intriguing and interesting. There are limitless possibilities regarding what you can achieve with internet and information scraping. While reading this write-up you've most likely wondered, "what are some excellent use cases for web/data scratching?
On the other hand, Python may be your best option if you are also curious about data Web Scraping science and also machine learning. These areas substantially benefit from having accessibility to huge sets of data. Therefore, by grasping Python, you can get the needed data via internet scratching, procedure it, and then directly apply it to your job. Cheerio Scraper is a ready-made service for crawling websites making use of plain HTTP requests.
https://maps.google.com/maps?saddr=1%20University%20Ave%20OFFICE%2005-103%2C%20Toronto%2C%20ON%20M5J%202P1%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
This is easy with Pandas considering that they have a simple feature for reviewing JSON right into a DataFrame. Up until now we've thought aspects exist in the tables we scraped, yet it's always a good suggestion to program scrapers in means so they do not damage when an aspect goes missing out on. Keep in mind, we have actually already checked our parsing above on a web page that was cached locally so we understand it functions. You'll wish to ensure to do this prior to making a loop that performs requests to stop needing to reloop if you neglected to parse something. Getting the link was a bit various than just choosing a component.
The humble guide to building an asset library - befores & afters
The humble guide to building an asset library.
Posted: Tue, 11 Jul 2023 11:15:42 GMT [source]
What is the difference in between ditching and creeping?
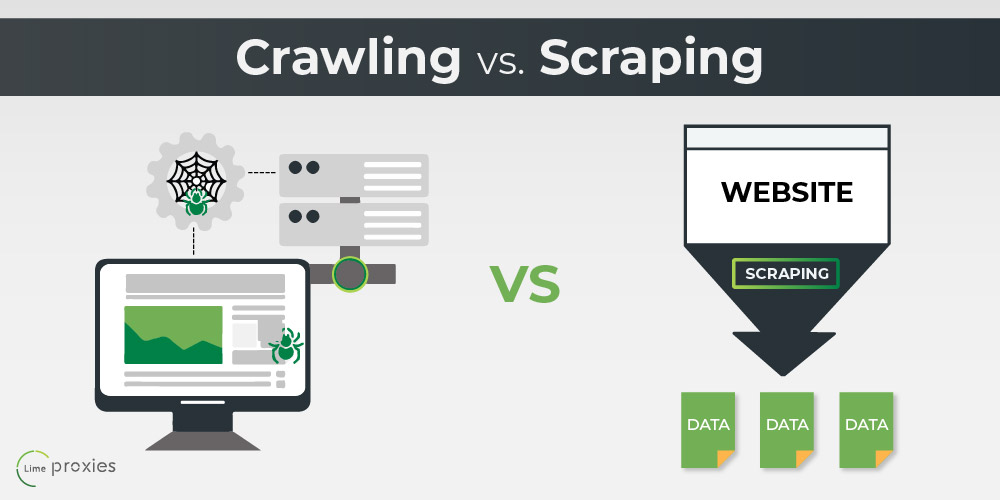
Web scratching objectives to remove the data on website, and also internet creeping functions to index as well as discover website. Web crawling entails following links permanently based upon hyperlinks. In comparison, web scuffing implies writing a program computing that can stealthily collect information from a number of sites.